October 2, 2023
Stuff I’ve built — Semantic Web plugins for Gmail and WordPress (2010)
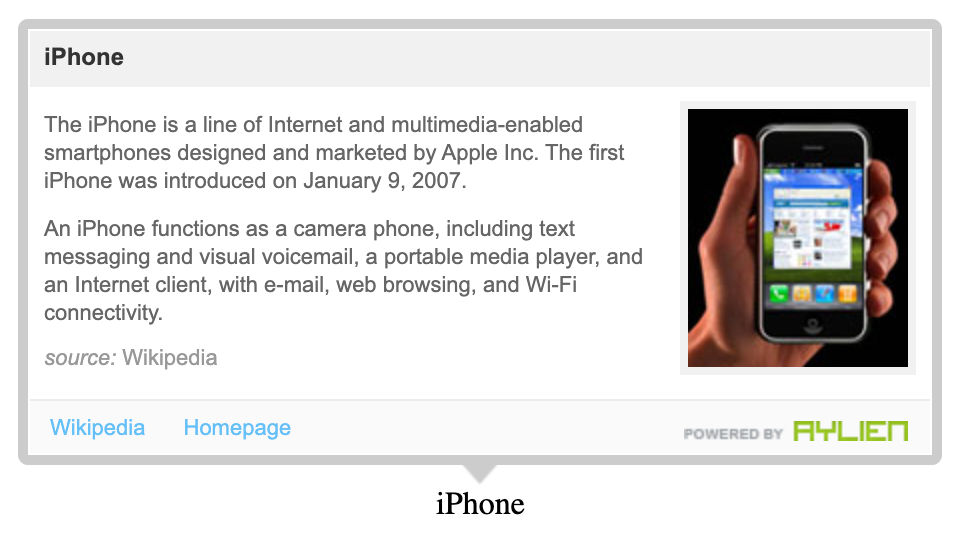 A WordPress plugin for adding context to your articles by tapping into the Semantic Web
A WordPress plugin for adding context to your articles by tapping into the Semantic Web
Lifetime revenue: $0
Collaborator(s): Soheil Alavi
Stage: Prototype
Technologies: Scala for APIs and NLP, OpenLink Virtuoso (graph DB to store DBpedia), HTML, CSS, and jQuery for the frontend
[Background]
In 2010, Semantic Web was all the rage. The idea that every company or organisation could standardise their data around an ontology and connect it up with every other organisation’s data into one giant graph that anyone could navigate was every computer scientist’s ultimate fantasy.
Tim Berners-Lee who invented the Web called it Web 2.0, and many thought it would become the foundation upon which the next Facebook or Google would be built, and so VC money was pouring into Semantic Web startups, and startups like Wavii, Qwiki, and Metaweb who later on got acquired by the likes of Google and Yahoo! were gaining a lot of traction.
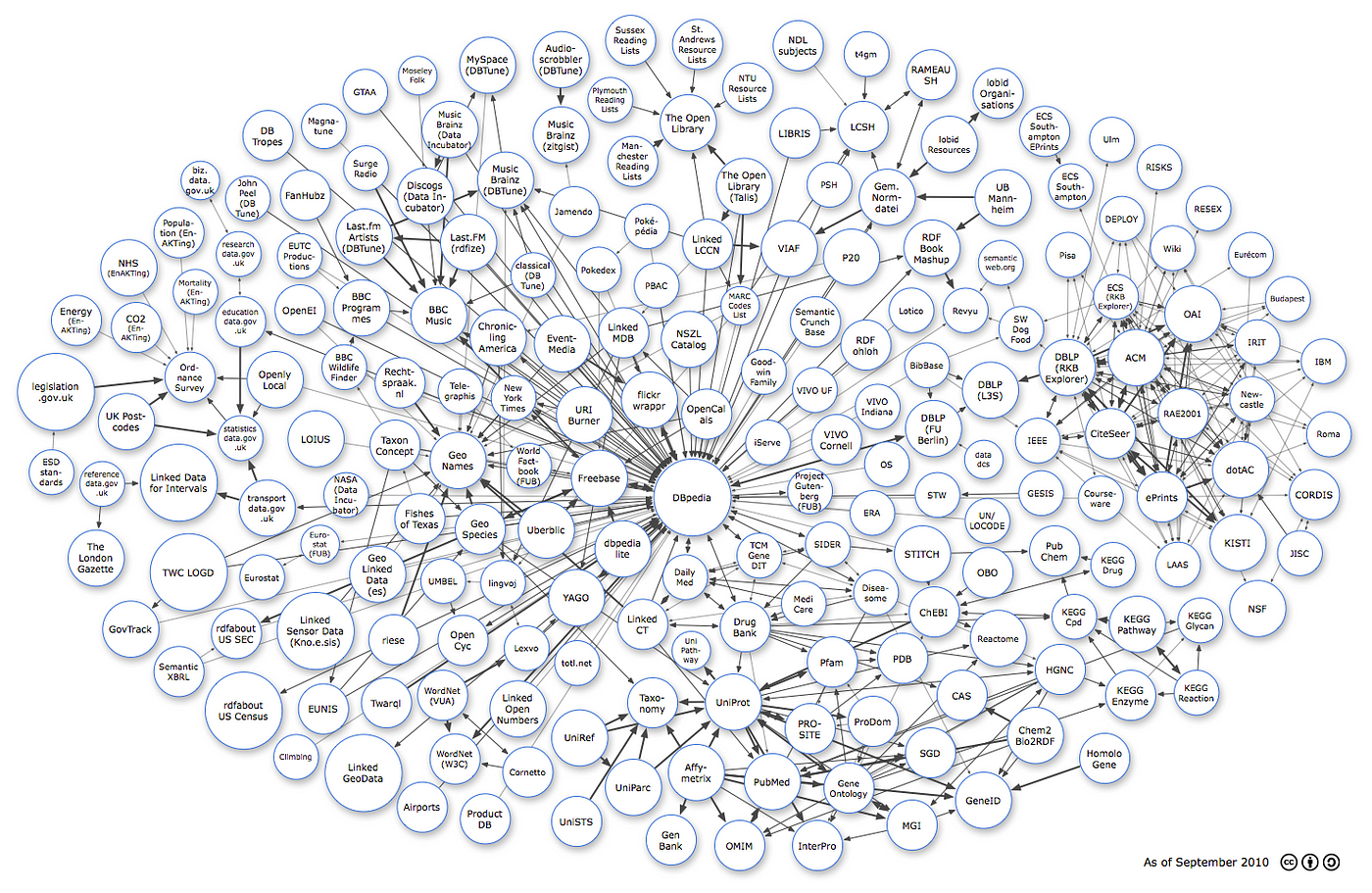 A map of Linked Open Data (LOD) in 2010
A map of Linked Open Data (LOD) in 2010
[The vision]
Most of the web back then (and probably today, if you exclude Instagram and TikTok) was in textual form and could not be easily linked to the Semantic Web. My vision was to connect textual data like emails, news articles, and blog posts to the Semantic Web, allowing users to tap into a world of relevant information behind the documents they were reading, as well as to help expand the portion of the web that was semantic.
The idea was to use natural language processing (NLP) to identify and tag all the entities and topics mentioned in any text, and to then link them to their corresponding entities (via URIs) in the Semantic Web.
Our vision for AYLIEN was to become the layer between textual data and the Semantic Web.
[The product]
We built 2 plugins both intended for end users:
- A Chrome extension that hijacked your Gmail sidebar (heavily inspired by Rapportive) to show you the key topics and entities mentioned in any email you were reading or writing, along with any additional information we could find in the Semantic Web, like Wikipedia abstracts, photos from Flickr, or stock prices from Yahoo! Finance.
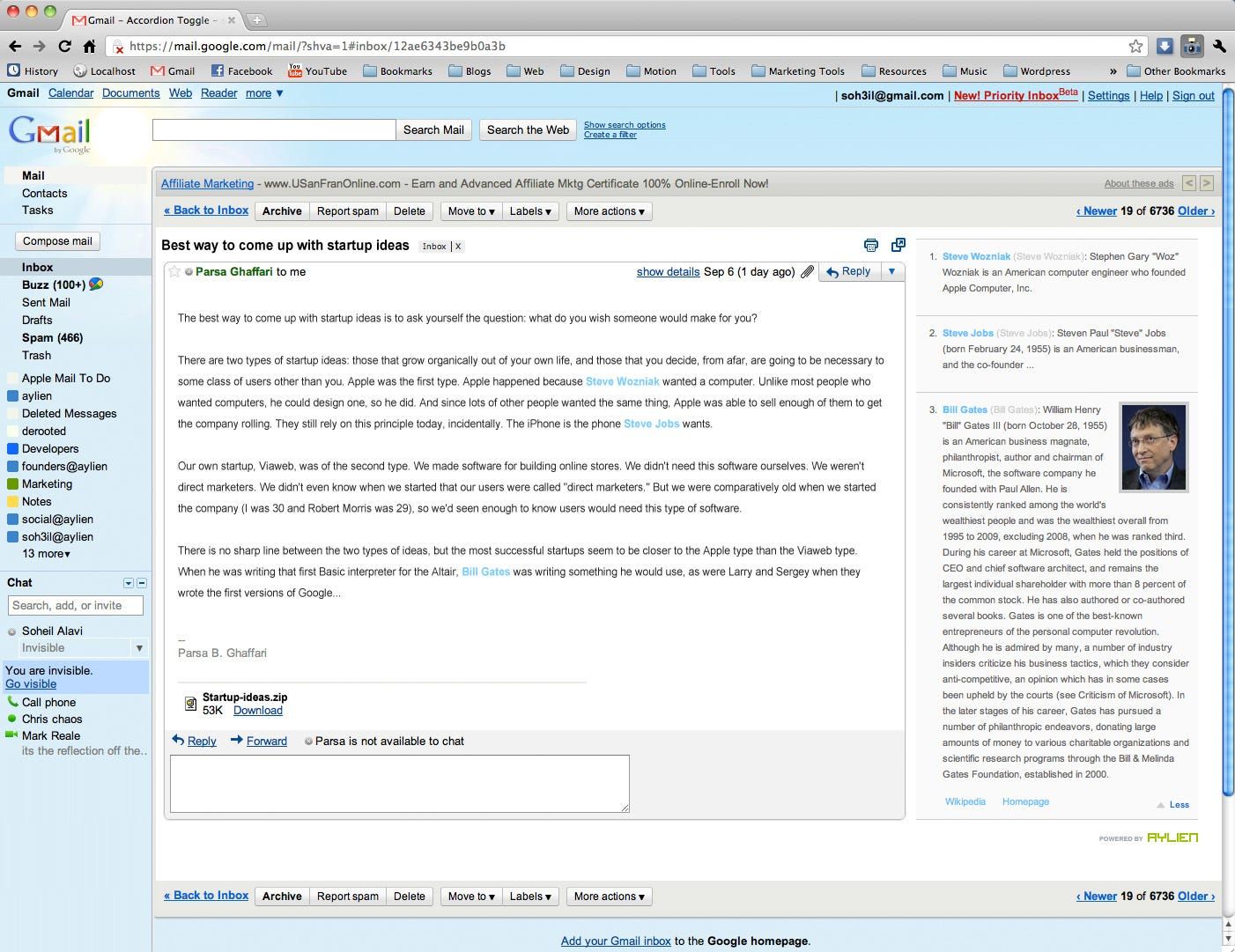 Our NLP would analyse your emails to extract mentions of people, companies, or topics, and show you some brief information about them in the sidebar
Our NLP would analyse your emails to extract mentions of people, companies, or topics, and show you some brief information about them in the sidebar
- A WordPress plugin that would analyse any article that you wrote to find out what you were talking about, then suggest relevant content from around the Semantic Web that you could drag and drop into your blog post.
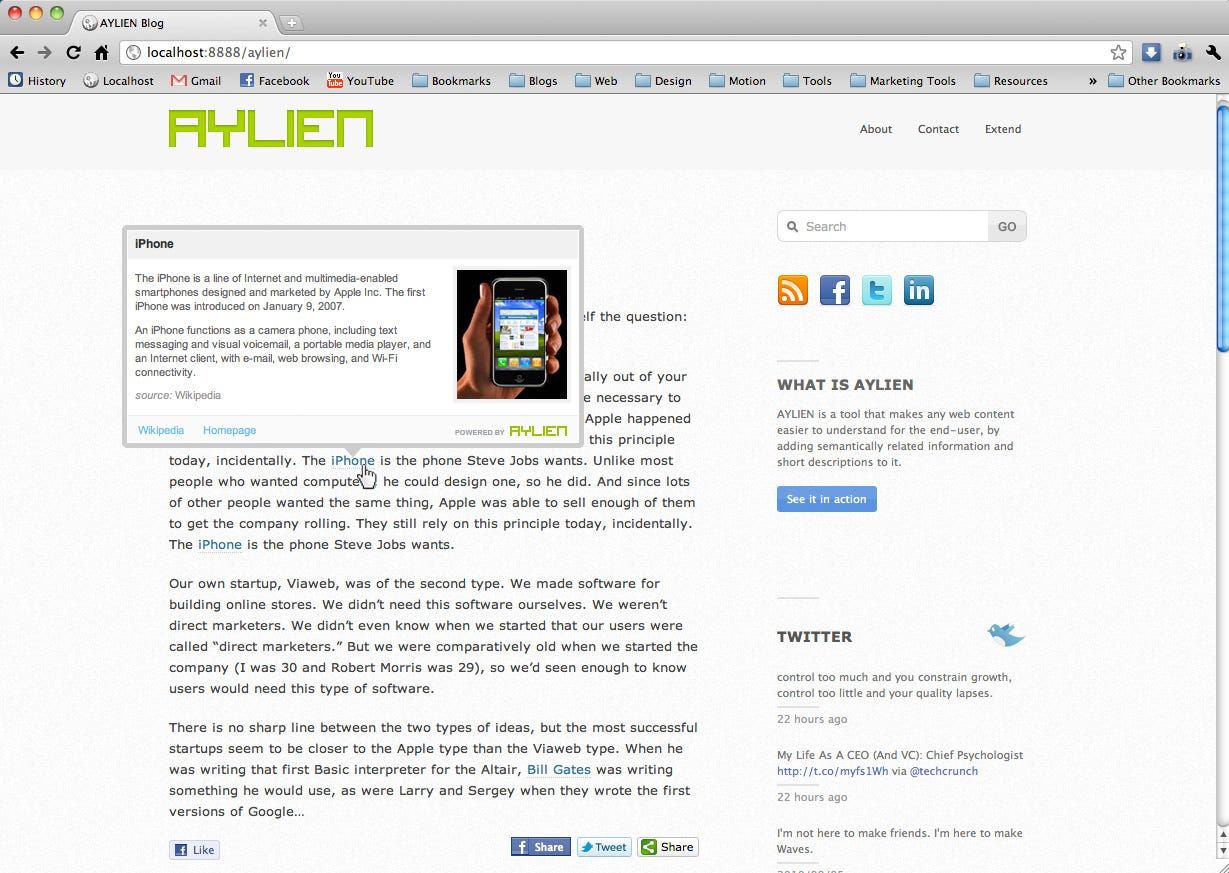 Our semantic tooltips were meant to give your readers additional context for the products or companies you were writing about
Our semantic tooltips were meant to give your readers additional context for the products or companies you were writing about
[What happened then]
The project fell apart after we hit a few roadblocks:
- Building a Gmail-hijacking browser extension was notoriously hard and fiddly back then
- NLP was notoriously hard back then, which is why we eventually focused on solving NLP for the average developer/data scientist with AYLIEN’s Text Analysis product
- Soheil and I decided we couldn’t work together and amicably parted ways
Despite all of this, we had built a compelling demo that showcased the potential of a mainstream application for the Semantic Web, and given how hot that space was back then, that demo helped us raise $500k in seed financing for AYLIEN and we were off to the races.
Previous post Why I love immunology (and why you should, too) The enigma that underpins death and disease If you were to die today, there’s a high chance you would die because of a failure in your immune Next post Visualising novels using Midjourney v6 and GPT-4 - Part 1: Characters Update 15/01/2024: Read part 2 on visualising key locations and events here Since finishing the last Harry Potter book in 2007, I hadn’t read much